
Une collègue a réalisé une symbologie catégorisée en utilisant un code couleur contenu dans un champ de la table.
Le souci est que QGIS ne sait pas encore faire les légendes qui vont bien pour cette sylmbologie, et, s’il affiche correctement ls données sur la carte, il conserve dans la légende les couleurs aléatoires.
La seule solution que j’ai trouvé consiste à créer un fichier de style et à la modifier à l’aide d’un éditeur de texte qui comprend les expressions régulières (jedit our moi mais aussi notepad++ ou d’autres).
Je réalise donc une symbologie catégorisée, sur un champ contenant le code de couleur suivi du libéllé (l’export en sld ne fonctionne pas sur une expression)
je crée le champ « libelle » composé de la concatenation des champs coul_hex et nom_ucs séparés par un trait d’union : « coulhex » ||’-‘|| « nom_ucs » pour que ce code couleur apparaisse quelque part dans mon fichier de style
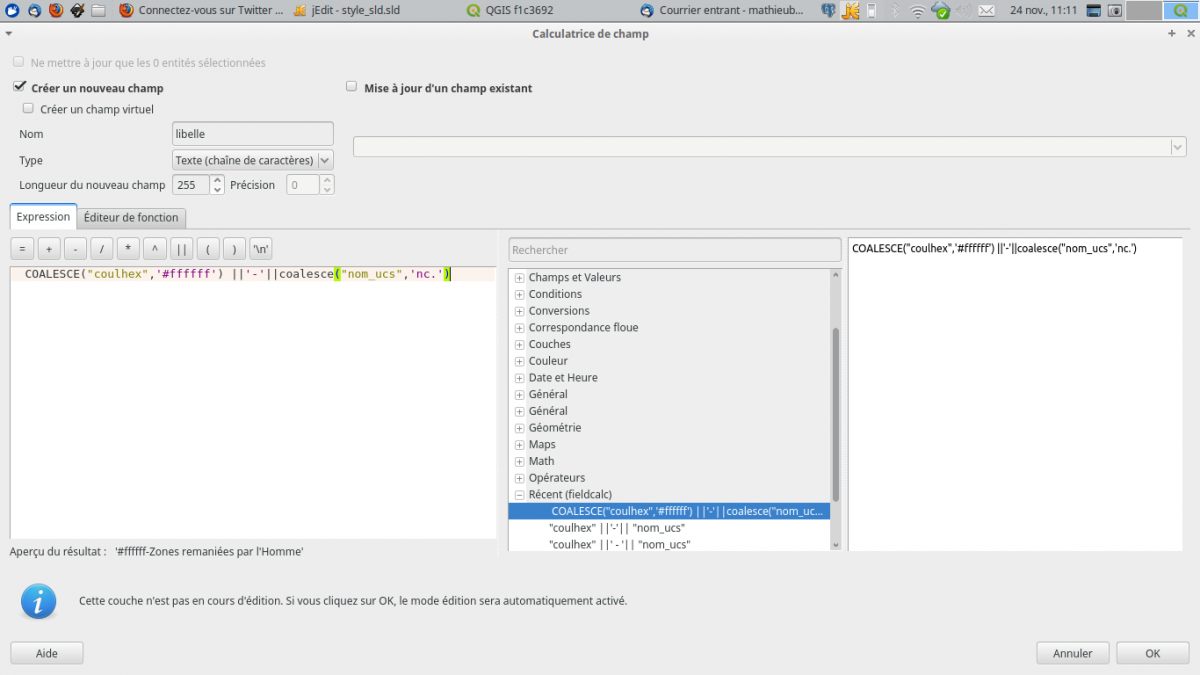
Je crée la symbologie sur ce champ :
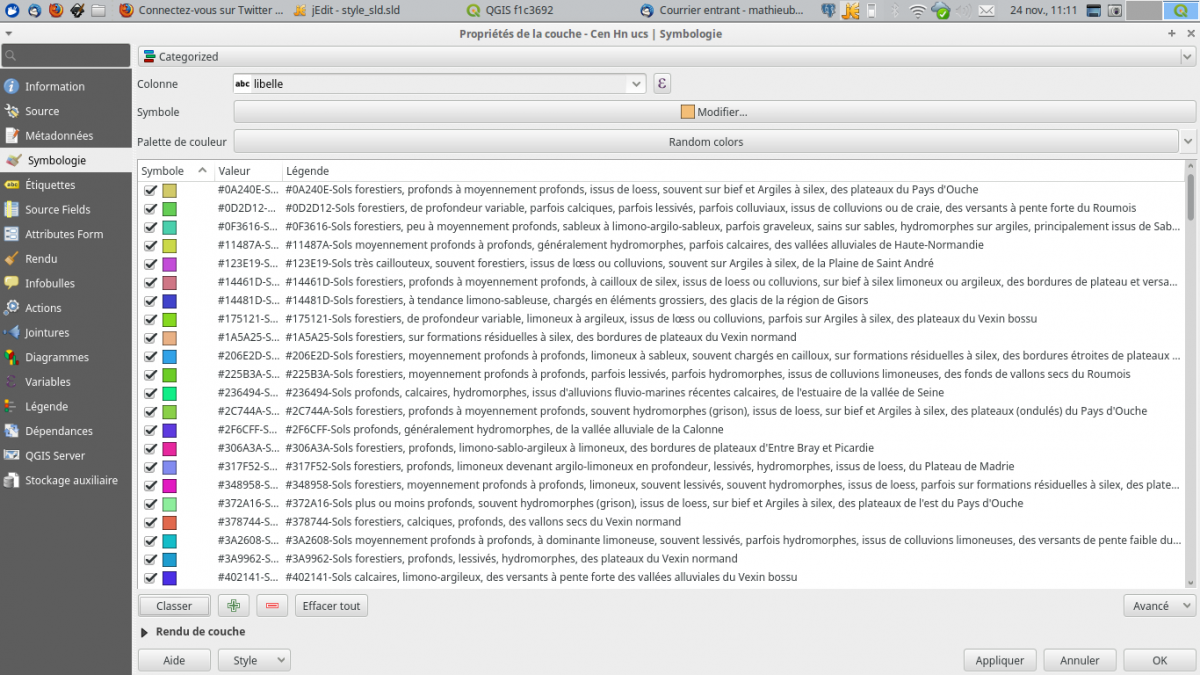
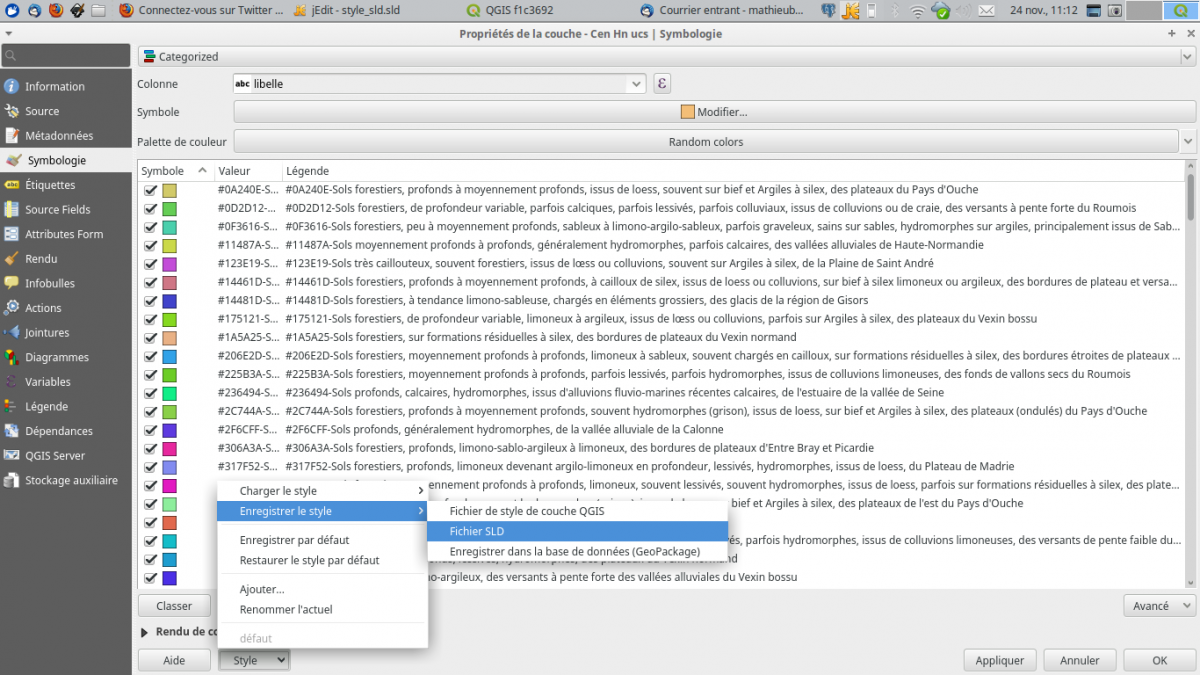
J’exporte cette symbologie dans un fichier de style sld (le format qml ne convient pas car il est constitué de deux blocs, un pour les symboles et le second pour les libellés) alors que dans le sld, libellé et couleur de symbole apparaiseent dans le même élément « rule » du xml.
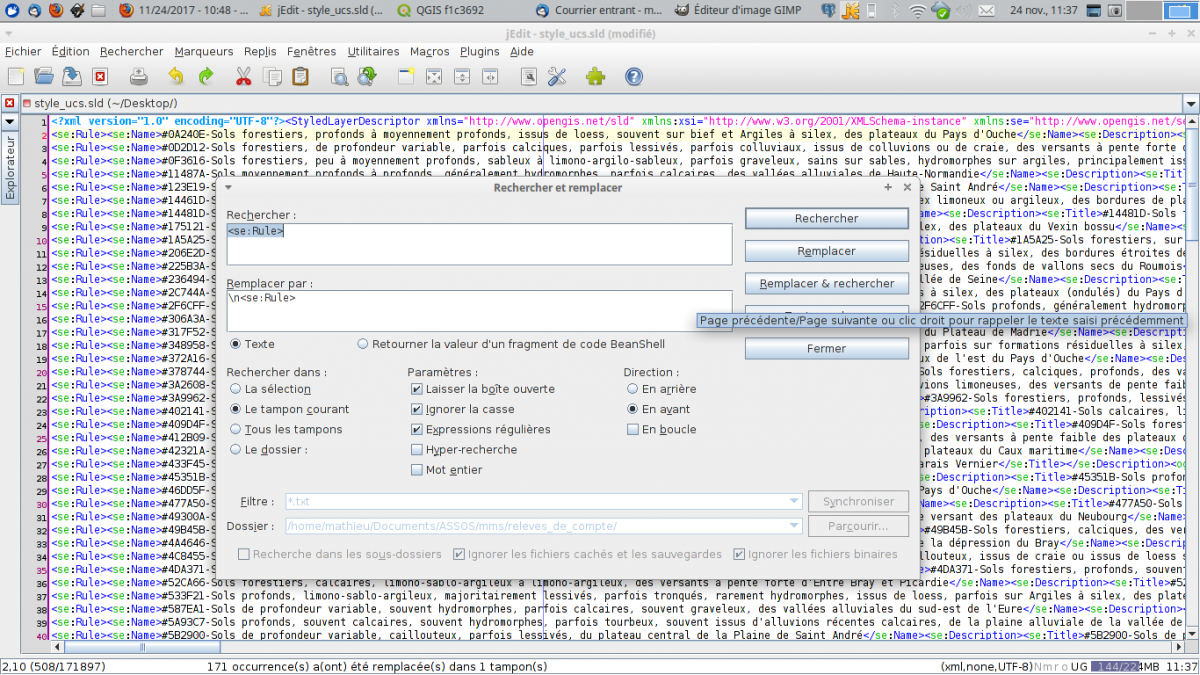
Si on regarde de plus prés comment ce fichier est écrit, on constate que chaque élément <se:Rule> contient d’une part la couleur de remplissage du symbole et d’autre part le libelle.

On va transformer le fichier pour que chaque règle soit sur une seule ligne.
On recherche donc l’expression régulière \n\s* qui signifie tous les sauts de ligne suivi ou non d’un espace, et va rempacer ça par rien. Le fichier se retrouve maintenant sur une seule ligne.
On va insérer un saut de ligne à chaque début de règle. On recherche donc le motif <se:Rule> qu’on remplace par le même, précédé d’un saut de ligne : \n<se:Rule>
Il nous reste « simplement » à remplacer le 4ème code couleur (celui attribué aléatoirement par QGIS pour le remplissage) par le premier.
On utilise l’expression régulière suivante :
^([^#]+)(#.{6})([^#]+#.{6}[^#]+#.{6}[^#]*)(#.{6})(.*)$
Les parenthèses ne servent qu’à capturer les motifs correspondant dans des variables ($1 à $n). A adapter selon votre éditeur de texte.
Donc l’expression dit ceci :
- La ligne commence (^) par n’importe quel caractère excepté # : [^#] répété au moin une fois + . Le tout est capturé dans $1.
- Suivent un # et 6 fois n’importe quel caractère : #.{6}+ . Le tout est capturé dans $2.
- On continue avec n’importe quel caractère excepté # répété au moin une fois [^#]+ puis un # et 6 fois n’importe quel caractère : #.{6}+ puis tout sauf # au moins une fois [^#]+ puis # et 6 fois n’importe quel caractère : #.{6}+ puis tout sauf # au moins une fois [^#]+. Le tout est capturé dans $3.
- Puis notre code de remplissage composé de # suivi de 6 caractères #.{6} stocké dans $4.
- Puis enfin n’importe quel catatère . 0 à n fois * jusque à la fin de la ligne $ : .*$
On remplace tout ça par le contenu de $1 auquel on ajoute $2 puis $3 puis $2 puis $5
Et le tour est joué.
Maintenant on souhaite peut-être nettoyer nos libellés et en enlever le code couleur. On va chercher/remplacer <se:Name>#.{6}- par <se:Name>. Pareil pour Title et Literal.
On va enfin dire qu’on applique ce style sur le champs nom_ucs qui contient uniquement le libelle en rempalçant <ogc:PropertyName>libelle par <ogc:PropertyName>nom_ucs
On enregistre notre fichier sld et on peut l’appliquer à notre couche QGIS. La colonne libelle ne sert plus, on peu la supprimer.
Il y a surement plus rapide, concis ou élégant mais c’est ce qui m’est venu dans le peu de temps que je m’étais accordé pour le faire.




 Dans notre cas, nous allons procéder au déploiement d’une application java sur un serveur Tomcat.
Dans notre cas, nous allons procéder au déploiement d’une application java sur un serveur Tomcat. Besoin simple
Besoin simple