Opérateurs, fonctions et requêtes spatiales
Introduction
Le support des données matricielles (raster) est une « nouveauté » de PostGIS 2.
A chaque pixel de la grille est associée une valeur (altitude, température, densité de population, type d’occupation du sol, perméabilité…). Cette valeur est stockée dans une bande.
PostGIS permet d’associer plusieurs bandes à un raster. On peut par exemple disposer d’un raster de températures mensuelles moyennes qui contient une bande par mois de l’année.
PostGIS stocke chaque raster dans une table de la base de données. La vue raster_columns est l’équivalent pour les raster de la vue geometry_columns pour les données vecteur.
Il offre la possibilité de tuiler le raster, c’est à dire de le fractionner en unités plus petites qui permettront d’accélérer les traitement en utilisant des index.
Chacune de ces tuiles un un carré de x pixels de coté. Chaque tuile (tile) orrespond à une ligne de la table. C’est à dire que la table qui contient le raster compte autant de lignes que le raster compte de tuiles.
De nombreuses opérations sont possibles avec les raster. Référez vous à l’aide de PostGIS1 pour avoir une vision complète des possibilités offertes, ainsi qu’à la présentation initiale du format par ses auteurs :
http://trac.osgeo.org/postgis/wiki/WKTRaster/Documentation01
Objectifs et organisation du TP
L’objectif de ce TP est de découvrir le type de données « raster » supporté par PostGIS depuis la version 2.0. Comme pour les données vectorielles utilisées au cours de deux précédents TP, ce TP va vous initier aux opérateurs, fonctions et requêtes spécifiques à ce type de données. Chacune des questions posées doit être traitée de la façon suivante :
-
Si cela n’est pas donné, recherche du ou des opérateurs et fonctions permettant de répondre à la question dans le cours ou dans la documentation de PostGIS.
-
Construction de la requête et répondre à la question
Pour une liste des opérateurs et fonctions spatiales ainsi que des exemples d’utilisation, vous pouvez vous référer à cette partie de la documentation PostGIS :
http://postgis.net/docs/reference.html
Une « cheat sheet » relative aux fonctions raster de PostGIS est disponible ici :
http://www.postgis.us/downloads/postgis21_cheatsheet.pdf
Pré-requis
Pour ce TP vous utiliserez la même base de données que pour les TP précédents. Nous utiliserons le client graphique PgAdmin pour l’affichage des tables et des résultats de requêtes.
Références et supports en ligne
Sites traitant de l’utilisation des rasters dans PostGIS
http://postgis.net/docs/manual-2.1/using_raster_dataman.html
Ajout des données Raster à la base de données
Données utilisées
Pour ce TP, nous allons utiliser les données raster du projet WorldClim (http://worldclim.org), disponibles à l’échelle de la planète sur internet :
l’altitude les variables bioclimatiques du projet worldclim :
-
BIO5 = Max Temperature of Warmest Month
-
BIO6 = Min Temperature of Coldest Month
Ces fichiers raster sont lourds (1.4 Go par variable), nous avons donc réalisé une extraction des données du territoire français (métropole et Corse). Vous trouverez ces données sur l’ENT.
En complément, nous allons ajouter à notre base de données la couche vecteur de l’ensemble des communes de France issues de la base de données GEOFLA de l’IGN :
http://professionnels.ign.fr/geofla
Utilisez Quantum Gis (ajout d’une couche raster) pour visualiser l’ensemble de ces couches. Les raster vont apparaître uniformément gris. Pour avoir une idée de la variabilité de la valeur des différents pixels, double cliquez sur chacune des couches. Dans l’onglet Style, choisissez « Bande grise unique » et modifiez la palette de couleur en choisissant «Pseudo-Couleurs »
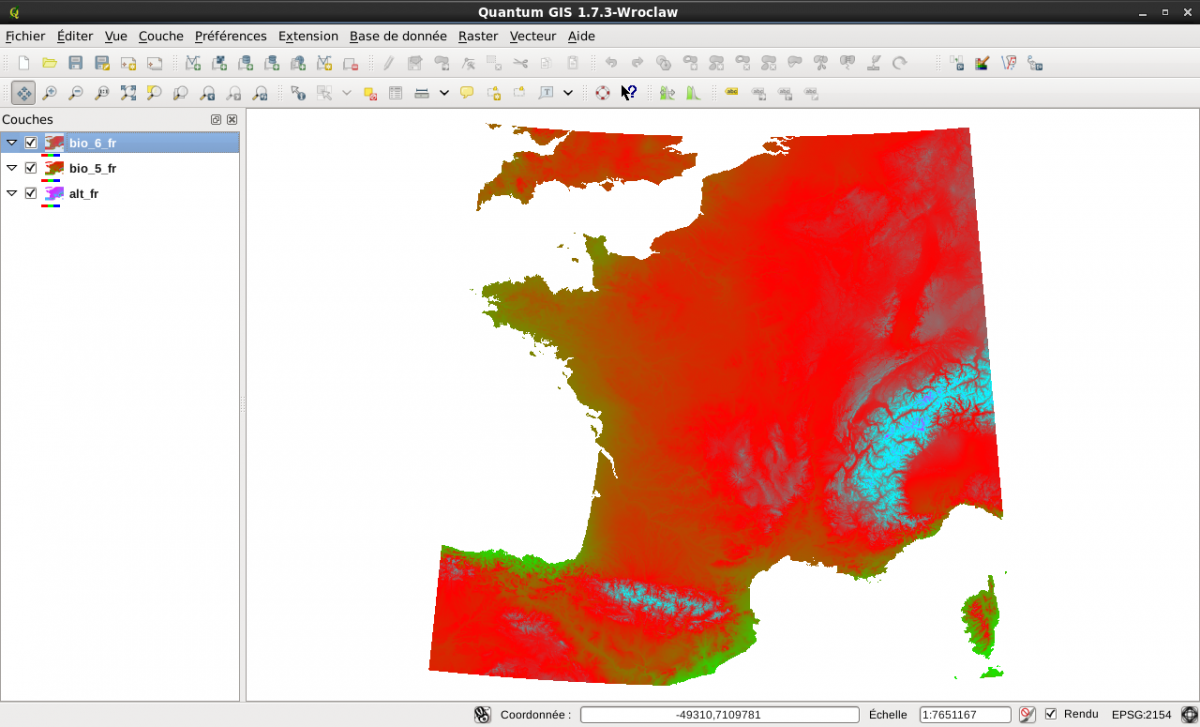
Ajout de la composante communale de GEOFLA à la table commune
Rendez vous dans le répertoire qui contient votre couche shp de la base de données geofla de l’iGN avec la commande « cd »
Shell> cd /home/…/geofla
Dans ce répertoire utilisez la commande shp2pgsql, vue au cours des séances précédentes pour ajouter ce shp à la base de données. La table de destination s’appellera « communes », la colonne géométrique sera nommée « geometrie », la projection utilisée sera le Lambert 93 (code EPSG 2154) et elle sera indexée.
Attention, l’encodage de cette couche est le LATIN1. La commande shp2pgsql dispose de l’option « W » qui vous permet de spécifier cet encodage.
Shell> shp2pgsql -s 2154 -g geometrie -I -W LATIN1 COMMUNE.SHP communes_france | psql -h gis -U login nom_base_de_données
Cette couche de données est en Lambert 93. Pour faciliter les calculs futurs, qui seront effectués sur des raster en WGS 84, nous allons ajouter une colonne géométrique en WGS 84 (nommée the_geom) à notre table des communes, la remplir et l’indexer. Vous pouvez utiliser PgAdmin3 ou psql pour écrire et exécuter ces requêtes.
psql> ALTER TABLE communes_france ADD column the_geom geometry(‘MULTIPOLYGON’,4326);
psql> UPDATE communes_france SET the_geom=st_transform(geometrie, 4326);
Mise à jour de la colonne « the_geom » de la table commune avec la géométrie contenue dan sla colonne « geometrie » reprojetée en WGS 84.
psql> CREATE INDEX communes_geom_gist ON communes_france USING gist (the_geom);
Création de l’index sur cette nouvelle colonne
Ajout des rasters à la base de données
Comme pour les données vecteur, PostGIS propose un chargeur de données en ligne de commande qui s’appelle raster2pgsql.
Consultez la documentation en ligne de PostGIS ou utilisez la commande suivante pour savoir quelles sont les options disponibles :
Shell> raster2pgsql – ?
Le système de coordonnées des grilles que nous allons intégrer à la base de données est le WGS 84 (code EPSG : 4326), nous créerons des tuiles de 5 pixels de coté et nous indexerons la table.
Nous intégrerons le raster bio_5_fr.tif dans une table nommée temperature_max, le raster bio_6_fr.tif dans une table nommée temperature_min et le raster d’élévation nommé alt_fr.tif dans une table nommée altitude.
Pour cela, rendez vous dans le répertoire contenant ces données avec la commande cd :
Shell> cd /chemin/vers/mes/donnees/raster
Shell> /chemin/vers/raster2pgsql -s 4326 -I -t 5×5 bio_5_fr.tif temperature_max | psql -h gis -U login nom_base_de_données
Shell> /chemin/vers/raster2pgsql -s 4326 -I -t 5×5 bio_6_fr.tif temperature_min | psql -h gis -U login nom_base_de_données
Shell> /chemin/vers/raster2pgsql -s 4326 -I -t 5×5 alt_fr.tif altitude | psql -h gis -U login nom_base_de_données
Requêtes géographiques avec PostGIS
Requêtes d’information sur les objets géographiques
Quelle est la taille des pixels des raster « temperature_min » et « temperature_max’ ? En quelle unité est-elle exprimée ?
Utilisez les fonctions ST_PixelHeight() et ST_PixelWidth()
De combien de tuiles sont composés chacun des raster ?
Quelle est la température minimale du centroïde de la commune de Montpellier ?
Vous utiliserez les fonctions ST_intersection(rast,the_geom) et ST_Centroïd(geometry)
Est-ce cohérent ? -> http://worldclim.org/faq
Quelle est la température minimale moyenne de la commune de Montpellier ?
Vous utiliserez la fonction ST_intersection(rast, the_geom) et l’opérateur d’agrégation AVG()
Quelle est la commune la plus chaude du département de l’Aude ?
Quelle est la commune la moins élevée du département des Pyrénées Orientales ?
Création et utilisation d’un raster multibande
Nous allons, pour simplifier les calculs utiliser la possibilité d’ajouter des bandes aux pixels du raster.
Commençons par ajouter au raster altitude une bande contenant la température minimale du mois le plus froid :
UPDATE altitude SET rast=ST_AddBand(altitude.rast, min.rast)
FROM temperature_min min
WHERE ST_UpperLeftX(min.rast) = ST_UpperLeftX(altitude.rast)
AND ST_UpperLeftY(min.rast) = ST_UpperLeftY(altitude.rast);
Ajoutons ensuite une bande contenant la température la plus élevée du mois le plus chaud :
UPDATE altitude SET rast=ST_AddBand(altitude.rast, max.rast)
FROM temperature_max max
WHERE ST_UpperLeftX(max.rast) = ST_UpperLeftX(altitude.rast)
AND ST_UpperLeftY(max.rast) = ST_UpperLeftY(altitude.rast);
Actualisons les informations relatives à nos tables contenues dans la tables raster_columns :
SELECT AddRasterConstraints(‘altitude’::name, ‘rast’::name);
SELECT AddRasterConstraints(‘temperature_min’::name, ‘rast’::name);
SELECT AddRasterConstraints(‘temperature_max’::name, ‘rast’::name);
Vérifions le nombre de bande de notre raster d’altitude :
SELECT num_bands FROM raster_columns WHERE r_table_name = ‘altitude’;
Requêtes complexes
Affichez l’altitude moyenne, la moyenne de la température la plus basse du mois le plus froid, la moyenne de la température la plus élevée du mois le plus chaud de la commune de Sanilhac-Sagries
Ajouter aux communes l’information relative à l’altitude de leur centroïde
-
ajouter un attribut « altitude » de type numeric à la table « communes_france »
-
mettre à jour la valeur de cette attribut en interrogeant le raster (utilisez la fonction st_value(rast, geometry), le code de la région est 91…
-
visualisez la couche dans Quantum Gis en utilisez une symbologie mettant en évidence la variation d’altitude
Bonus pour aller plus loin
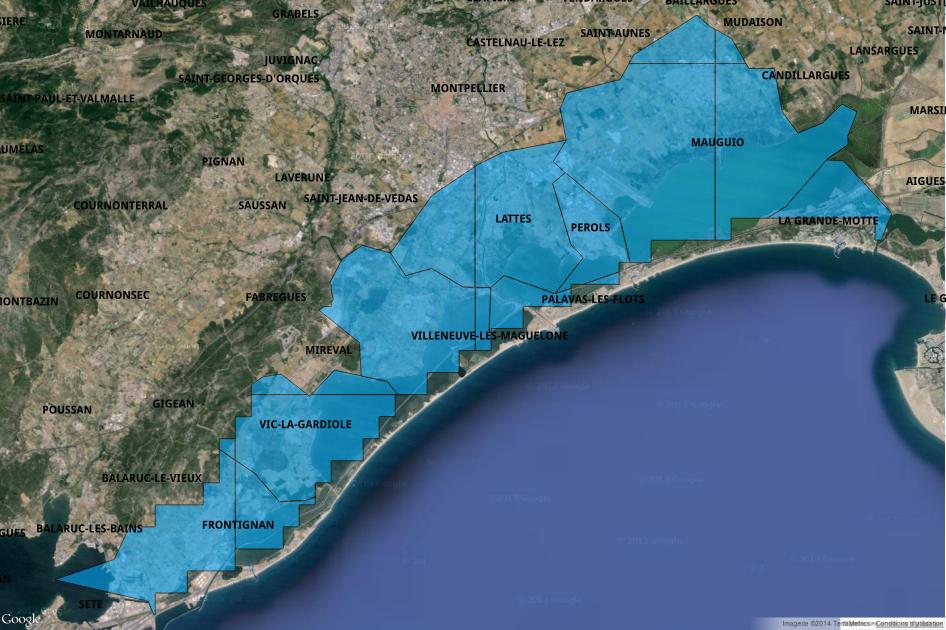
Extraire du MNT les zones basses (altitude < 50 cm) des communes littorales de la région de Montpellier (PALAVAS, LATTES, MAUGUIO, PEROLS, LA GRANDE-MOTTE, VILLENEUVE LES MAGUELONE, VIC LA GARDIOLE, FRONTIGNAN)
On extrait tout d’abord la géométrie et la valeur de chacun des pixels de la table altitude qui sont contenus dans les communes littorales
SELECT communes_france.nom_comm, (st_intersection(altitude.rast, communes.the_geom)).val AS val,
(st_intersection(altitude.rast, communes.the_geom)).geom AS geom
FROM communes_france, altitude
WHERE communes_france.nom_comm::text ILIKE ANY(array[‘PALAVAS%’,’LATTES%’,’MAUGUIO%’,’PEROLS%’,’%GRANDE-MOTTE%’,’%MAGUELONE’,’%GARDIOLE’,’FRONTIGNAN’]) AND st_intersects(altitude.rast, communes_france.the_geom)
De cet ensemble de géométries et de valeurs, nous allons extraire et regrouper les géométrie des pixels de moins de 50 m d’altitude
WITH valeurs_tous_pixels AS (
SELECT communes_france.nom_comm, (st_intersection(altitude.rast, communes_france.the_geom)).val AS val, (st_intersection(altitude.rast, communes_france.the_geom)).geom AS geom
FROM communes_france, altitude
WHERE communes_france.nom_comm::text ILIKE ANY(array[‘PALAVAS%’,’LATTE%’,
‘MAUGUIO%’,’PEROLS%’,’%GRANDE-MOTTE %’,’%MAGUELONE’,’%GARDIOLE’,’FRONTIGNAN’])
AND st_intersects(altitude.rast, communes_france.the_geom)
)
SELECT valeurs_tous_pixels.nom_comm, avg(valeurs_tous_pixels.val) AS moyenne_temp_min, st_union(valeurs_tous_pixels.geom) AS the_geom
FROM valeurs_tous_pixels
WHERE valeurs_tous_pixels.val < 50::double precision
GROUP BY valeurs_tous_pixels.nom_comm;
On crée la vue.
CREATE OR REPLACE VIEW zone_inondable AS …
Solution proposée
-- 3.1.3
SELECT nom_comm,
--(ST_intersection(rast, st_centroid(the_geom))).val,
ST_value(rast,1,st_centroid(the_geom))
FROM communes_france, temperature_min
WHERE nom_comm = 'MONTPELLIER'
AND st_intersects(rast,st_centroid(the_geom)) -- pour rendre la requête plus rapide
;
-- 3.1.4
SELECT nom_comm, avg(val)/10 AS temp_min_moyenn
FROM (
SELECT nom_comm,
(ST_intersection(rast, the_geom)).val
FROM communes_france, temperature_min
WHERE nom_comm = 'MONTPELLIER'
AND st_intersects(rast,the_geom)
) AS valeur_des_differents_raster -- Les sous-requêtes doivent être "nommées"
GROUP BY nom_comm;
/* Alternative en utilisant les CTE (Comman table expression)
http://www.postgresql.org/docs/9.0/static/queries-with.html */
WITH valeur_des_differents_raster AS (
SELECT nom_comm,
(ST_intersection(rast, the_geom)).val
FROM communes_france, temperature_min
WHERE nom_comm = 'MONTPELLIER'
AND st_intersects(rast,the_geom)
)
SELECT nom_comm, avg(val)/10 AS moyenne_temp_min
FROM valeur_des_differents_raster
GROUP BY nom_comm;
-- 3.1.5
SELECT nom_comm, avg(val)/10 AS moyenne_temp_max
FROM (
SELECT nom_comm,
(ST_intersection(rast, the_geom)).val
FROM communes_france, temperature_max
WHERE code_dept = '11'
AND st_intersects(rast,the_geom)
) AS valeur_des_differents_raster
GROUP BY nom_comm
ORDER BY 2 DESC LIMIT 1;
-- 3.1.6
SELECT nom_comm, avg(val) AS moyenne_altitude
FROM (
SELECT nom_comm,
(ST_intersection(rast, the_geom)).val
FROM communes_france, altitude
WHERE code_dept = '34'
AND st_intersects(rast,the_geom)
) AS valeur_des_differents_raster
GROUP BY nom_comm
ORDER BY 2 ASC LIMIT 1;
-- 3.3.1
SELECT nom_comm, avg(altitude) AS moyenne_altitude, avg(temp_min)/10 AS moyenne_temp_min, avg(temp_max)/10 AS moyenne_temp_max
FROM (
SELECT nom_comm,
(ST_intersection(the_geom, rast, 1)).val AS altitude,
(ST_intersection(the_geom, rast, 2)).val AS temp_min,
(ST_intersection(the_geom, rast, 3)).val AS temp_max
FROM communes_france, altitude
WHERE lower(nom_comm) = lower('Sanilhac-Sagries')
AND st_intersects(rast,the_geom)
) AS valeur_des_differents_raster
GROUP BY nom_comm
ORDER BY 2 ASC LIMIT 1;
-- 3.3.2
ALTER TABLE communes ADD COLUMN altitude numeric;
UPDATE communes SET altitude = ST_VALUE(rast, 1, ST_CENTROID(the_geom))
FROM altitude WHERE ST_INTERSECTS(rast, ST_CENTROID(the_geom));

 Le nouveau protocole national et la charte régionale du SINP ont été discutés, partagés et adoptés en concertation au printemps 2013.
Le nouveau protocole national et la charte régionale du SINP ont été discutés, partagés et adoptés en concertation au printemps 2013.