L'édition 2018 de la réunion "Carnets de terrain électroniques" du CNRS a été l'occasion de revenir sur 12 années d'alimentation de notre base de données PostGIS par divers outils.
Le programme de la réunion : http://rbdd.cnrs.fr/spip.php?article270
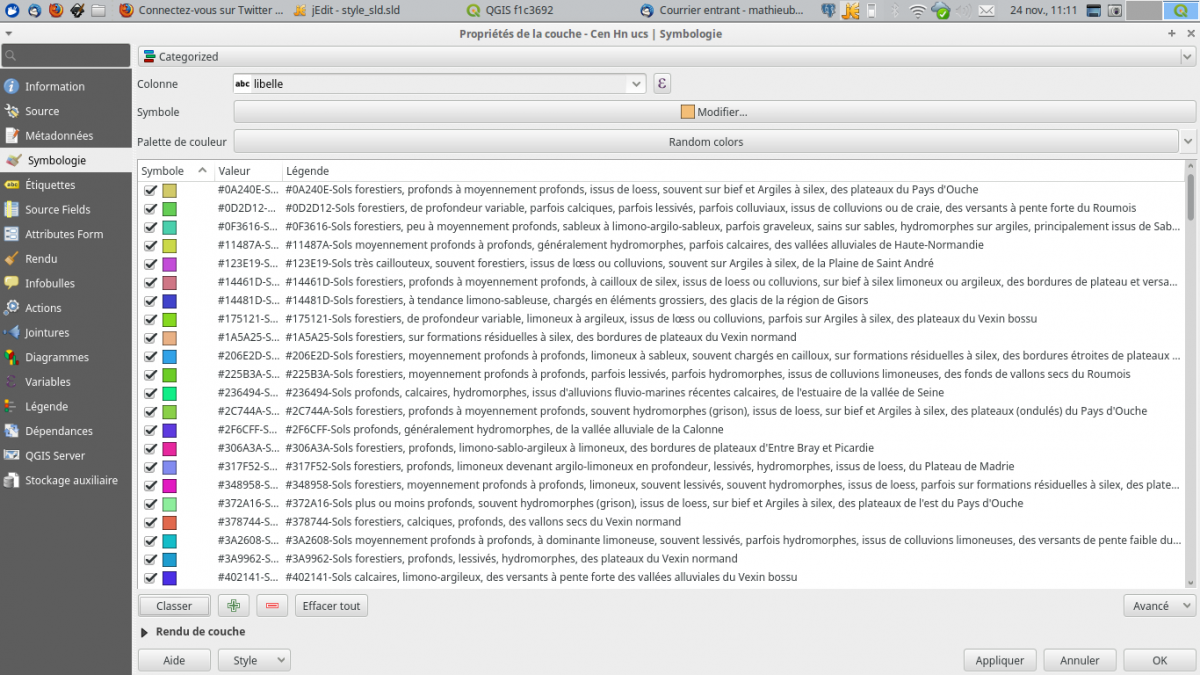
Une collègue a réalisé une symbologie catégorisée en utilisant un code couleur contenu dans un champ de la table.
Le souci est que QGIS ne sait pas encore faire les légendes qui vont bien pour cette sylmbologie, et, s’il affiche correctement ls données sur la carte, il conserve dans la légende les couleurs aléatoires.
La seule solution que j’ai trouvé consiste à créer un fichier de style et à la modifier à l’aide d’un éditeur de texte qui comprend les expressions régulières (jedit our moi mais aussi notepad++ ou d’autres).
Je réalise donc une symbologie catégorisée, sur un champ contenant le code de couleur suivi du libéllé (l’export en sld ne fonctionne pas sur une expression)
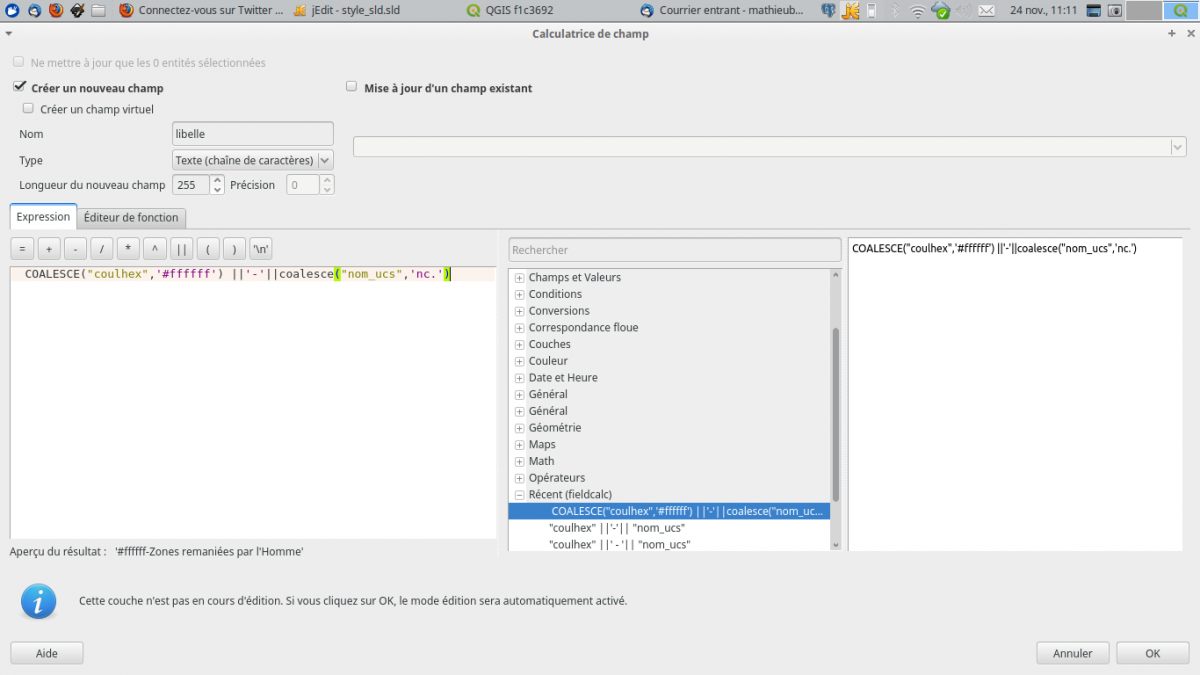
je crée le champ « libelle » composé de la concatenation des champs coul_hex et nom_ucs séparés par un trait d’union : « coulhex » ||’-‘|| « nom_ucs » pour que ce code couleur apparaisse quelque part dans mon fichier de style
Je crée la symbologie sur ce champ :
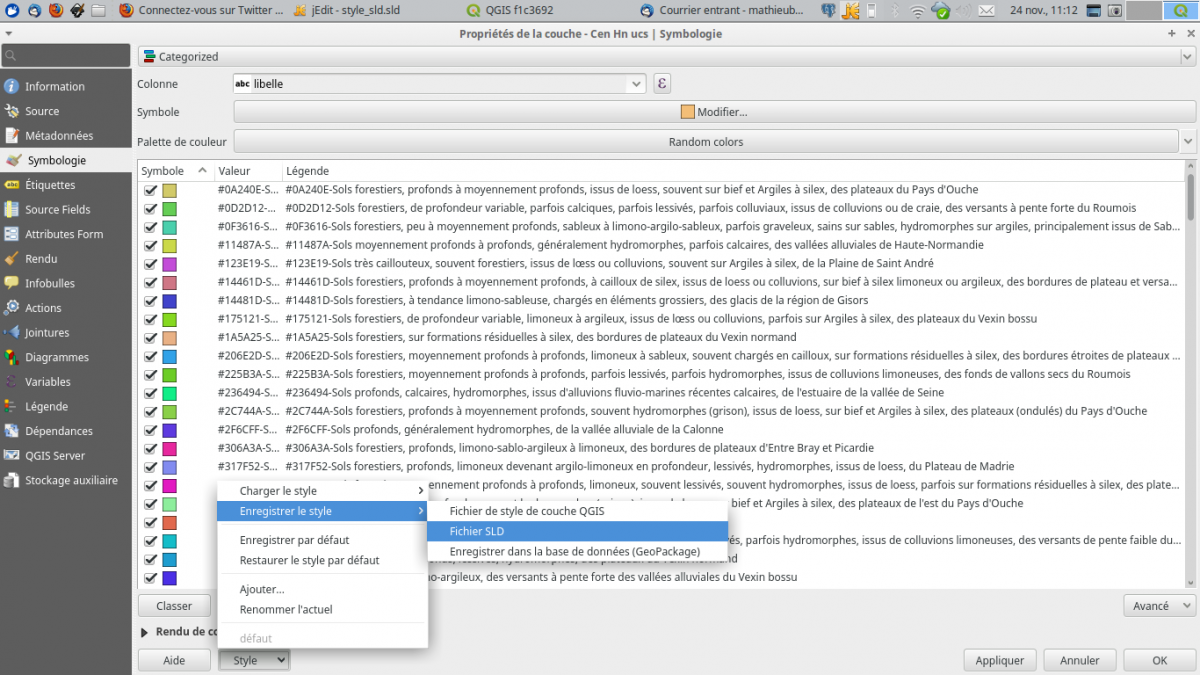
J’exporte cette symbologie dans un fichier de style sld (le format qml ne convient pas car il est constitué de deux blocs, un pour les symboles et le second pour les libellés) alors que dans le sld, libellé et couleur de symbole apparaiseent dans le même élément « rule » du xml.
Si on regarde de plus prés comment ce fichier est écrit, on constate que chaque élément <se:Rule> contient d’une part la couleur de remplissage du symbole et d’autre part le libelle.
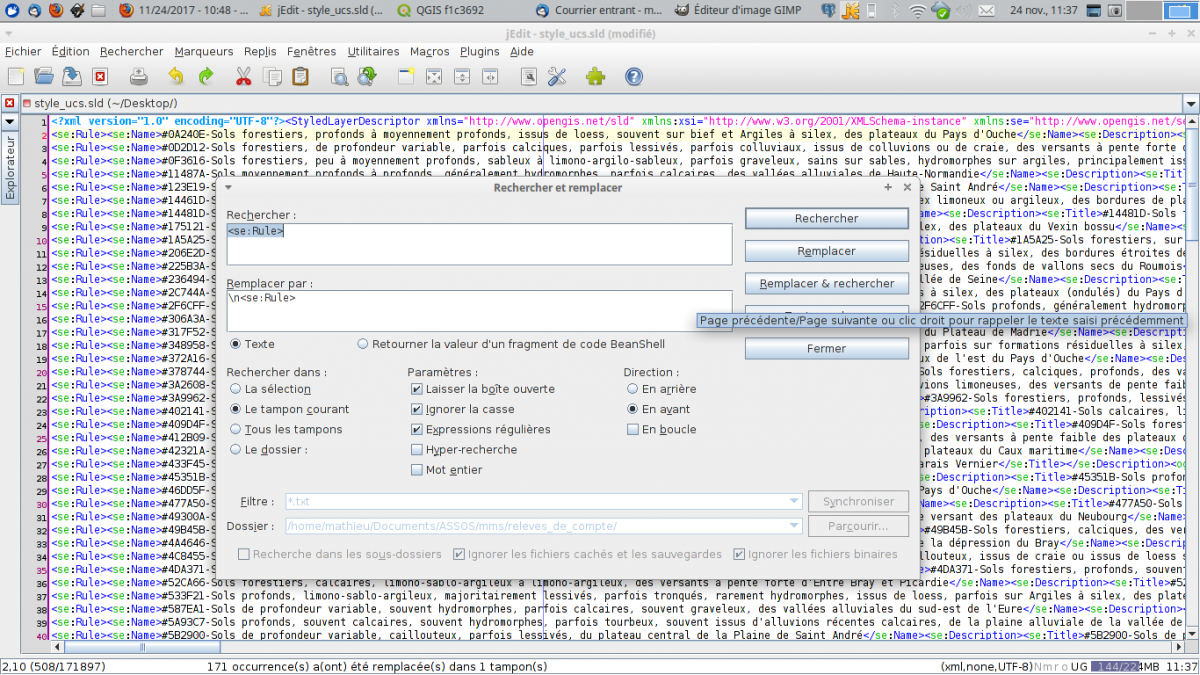
On va transformer le fichier pour que chaque règle soit sur une seule ligne.
On recherche donc l’expression régulière \n\s* qui signifie tous les sauts de ligne suivi ou non d’un espace, et va rempacer ça par rien. Le fichier se retrouve maintenant sur une seule ligne.
On va insérer un saut de ligne à chaque début de règle. On recherche donc le motif <se:Rule> qu’on remplace par le même, précédé d’un saut de ligne : \n<se:Rule>
Il nous reste « simplement » à remplacer le 4ème code couleur (celui attribué aléatoirement par QGIS pour le remplissage) par le premier.
Les parenthèses ne servent qu’à capturer les motifs correspondant dans des variables ($1 à $n). A adapter selon votre éditeur de texte.
Donc l’expression dit ceci :
La ligne commence (^) par n’importe quel caractère excepté # : [^#] répété au moin une fois + . Le tout est capturé dans $1.
Suivent un # et 6 fois n’importe quel caractère : #.{6}+ . Le tout est capturé dans $2.
On continue avec n’importe quel caractère excepté # répété au moin une fois [^#]+ puis un # et 6 fois n’importe quel caractère : #.{6}+ puis tout sauf # au moins une fois [^#]+ puis # et 6 fois n’importe quel caractère : #.{6}+ puis tout sauf # au moins une fois [^#]+. Le tout est capturé dans $3.
Puis notre code de remplissage composé de # suivi de 6 caractères #.{6} stocké dans $4.
Puis enfin n’importe quel catatère . 0 à n fois * jusque à la fin de la ligne $ : .*$
On remplace tout ça par le contenu de $1 auquel on ajoute $2 puis $3 puis $2 puis $5
Et le tour est joué.
Maintenant on souhaite peut-être nettoyer nos libellés et en enlever le code couleur. On va chercher/remplacer <se:Name>#.{6}- par <se:Name>. Pareil pour Title et Literal.
On va enfin dire qu’on applique ce style sur le champs nom_ucs qui contient uniquement le libelle en rempalçant <ogc:PropertyName>libelle par <ogc:PropertyName>nom_ucs
On enregistre notre fichier sld et on peut l’appliquer à notre couche QGIS. La colonne libelle ne sert plus, on peu la supprimer.
Il y a surement plus rapide, concis ou élégant mais c’est ce qui m’est venu dans le peu de temps que je m’étais accordé pour le faire.
Ce problème est remonté par QGIS avec le message d’erreur suivant : ERROR: cannot perform INSERT RETURNING on relation xxx
HINT: You need an unconditional ON INSERT DO INSTEAD rule with a RETURNING clause.
CREATE TRIGGER saisie_habitat_ON_INSERT
INSTEAD OF INSERT ON habitats_naturels.saisie_habitats_avec_ref
FOR EACH ROW EXECUTE PROCEDURE habitats_naturels.saisie_habitat_insert();
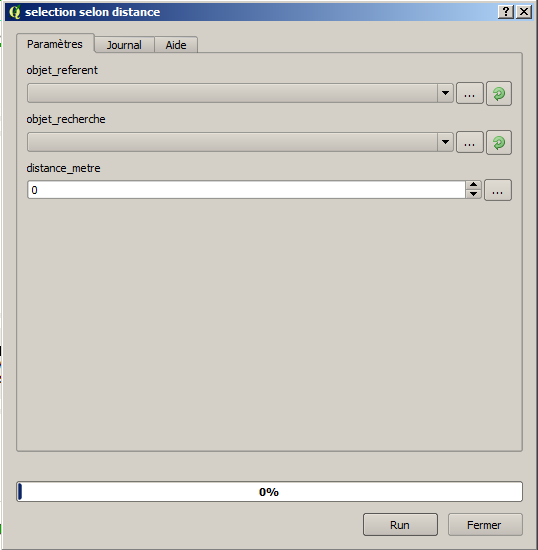
Un collègue bien embarrassé nous a posé la question suivante : comment sélectionner tous les points d’une couche A qui se trouvent à moins de 4km d’une autoroute.
Le postulat de départ est que nous travaillons sur des fichiers shp (donc on oublie tout de suite la requête sql et l’opérateur st_dwithin() )
Nous avons tous répondu « tu crées un tampon de 4km de rayon autour de l’autoroute puis tu fais une recherche par localisation de tous les objets de la couche de points qui intersectent le tampon créé« .
Il nous a répondu « ok ça je sais le faire mais la personne qui m’a posé cette question m’a tendu un piège pour me dire que c’était fou de devoir passer par un tampon, alors que d’autre outils font ça en un clic…« .
L’objectif sous-jacent et l’effet attendu auprés de l’assistance -non « géomaticienne »- semble être de vouloir déprécier QGIS.
Considérons donc que cette personne n’est pas fan de SQL et qu’elle affectionne le format shp.
Tout d’abord, quel problème y-a-t-il à devoir créer un tampon ?
Aucun… Si les géomaticiens en avaient assez de créer des fichiers à tout va, tous travailleraient en SQL dans une base de données spatiales. Par ailleurs QGIS permet de générer le tampon en mémoire, sans passer par l’écriture d’un fichier sur le disque. Le souci n’est donc pas là.
Peut-être réside-t-il dans le fait de ne pas disposer d’un clique-bouton pour faire le travail et de devoir passer par deux étapes ?
Une des qualités de tout bon géomaticien n’est-elle pas de savoir résoudre un problème qui se pose à lui, avec les outils dont il dispose. Si l’absence de bouton pour faire le travail est un obstacle rédibitoire, changeons tout de suite de métier.
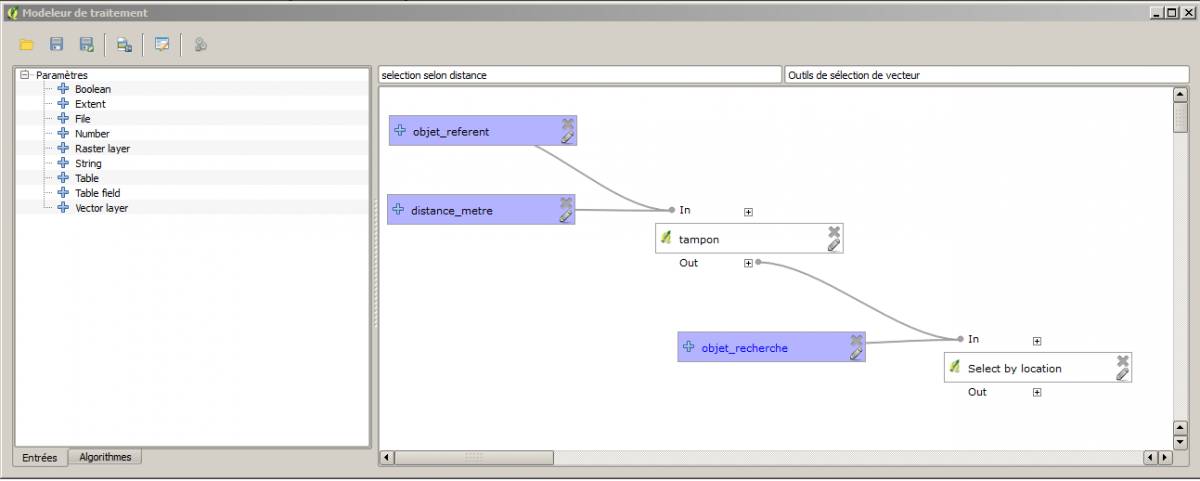
Mais qu’à cela ne tienne. Il me faut un clique-bouton donc je le crée !
Modeleur graphique et boite à outils « traitements »
Le modèle de traitement qui résulte de cette opération est accessible ici en téléchargement.
L’interface produite est la suivante :
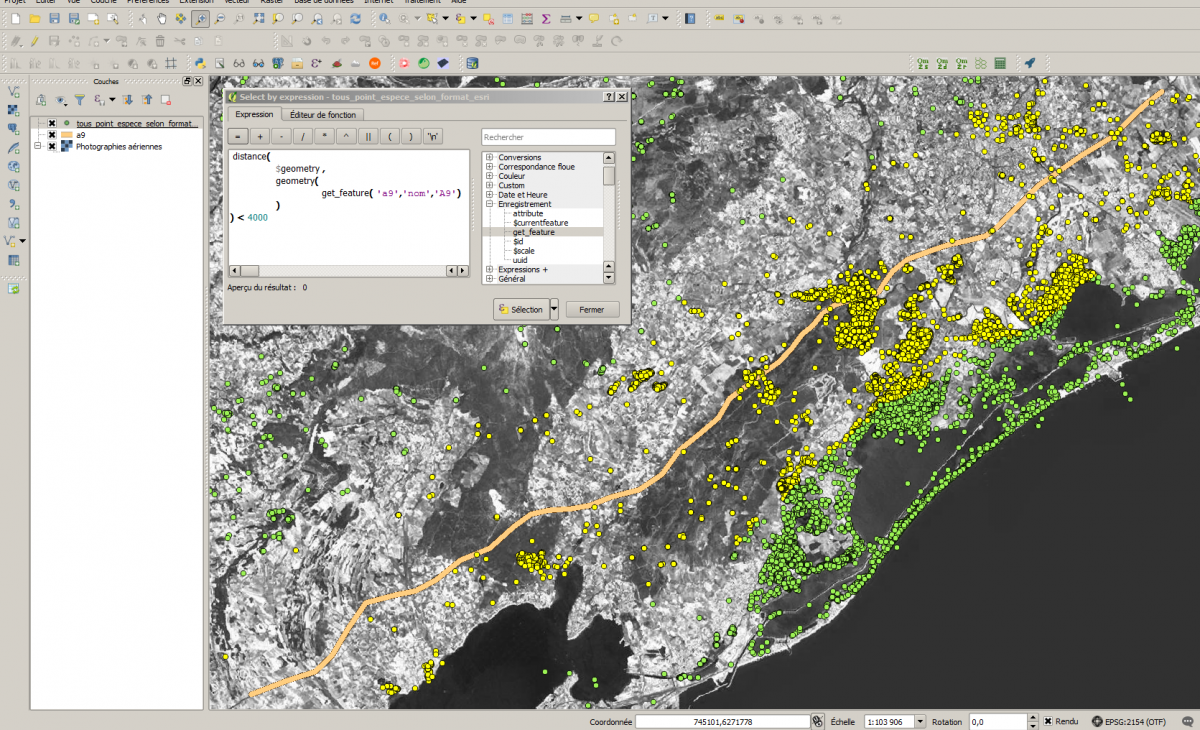
Sélection par expression
Une autre possibilité offerte part QGIS réside dans l’utilisation d’expressions pour la sélection.
Je peux donc sélectionner dans une couche de points, tous les objets dont la géometrie est à une certaine distance d’un objet d’une autre couche (ici une ligne).
Présentation réalisée et enregistrée dans le cadre du séminaire « Système d’information embarqué, cahier/carnet de terrain et de laboratoire électronique : quelles interactions avec les bases de données ? »
le Mercredi 05 octobre 2016 à Paris – Jussieu (amphi Charpak).
Cliquez sur l’image ci-dessous pour accéder à la vidéo.
Je partage ici un trés gros travail réalisé par les collègues géomaticiens du CEN Picardie (Jérôme Boutet, Marie Héraude, et Gratien Testud) qui ont actualisé le document « Aide-mémoire SIG et Quantum GIS Lisboa 1.8 », réalisé en 2013 par Guillaume Doucet du CEN Bourgogne.
Les démarches présentées sont généralisables et répétables.
La première présentation concerne des cas d’utilisation d’outils de « reporting » qui croisent connaissance naturaliste et données foncière, pour informer un acquéreur ou un vendeur sur les enjeux connus sur les parcelles concernées ou plus classiquement pour informer un propriétaire de l’intérêt patrimonial de sa propriété :
Chaque version de ligne de la table saisie.saisie_observation y est datée (date_operation). La fenêtre est une partition réalisée selon id_obs et ordonnée par date_operation. Les fonctions window sont expliquées ici dans la doc de postgresql :
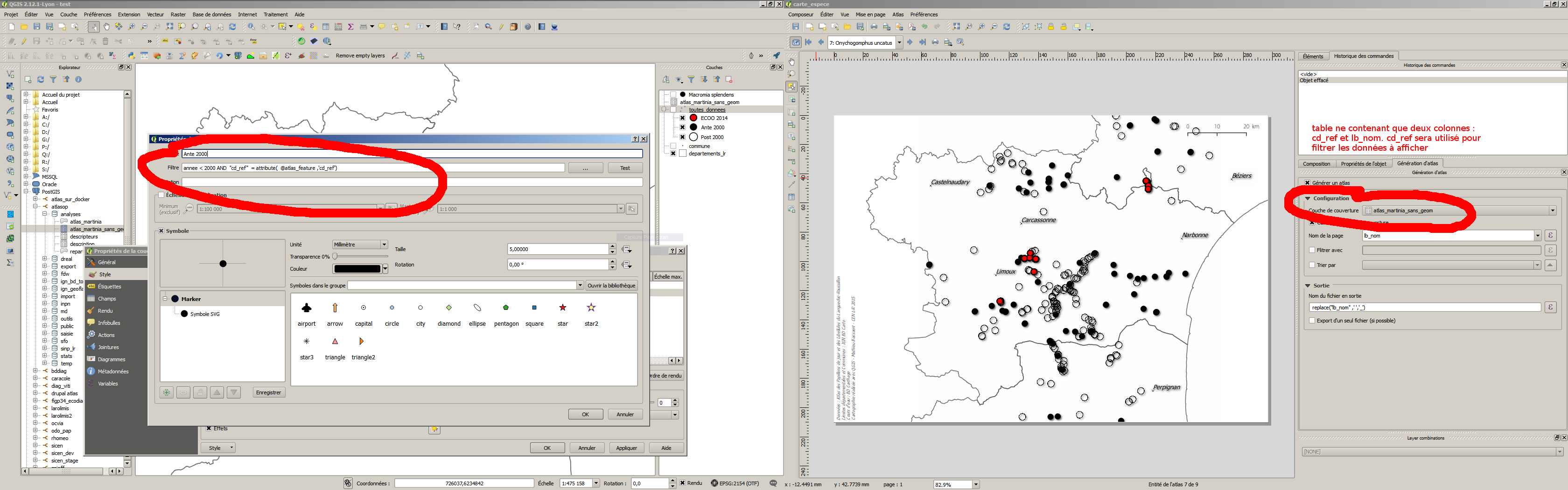
Suite aux discussions des journées utilisateurs de QGIS des 10 et 11 décembre. J’ai testé l’utilisation d’une table atributaire comme couche de couverture. Et ça fonctionne !
Je ne sais pas si c’était le cas sur les versions précédentes mais ça fonctionne sur la 2.12. Ma table ne contient que deux colonnes cd_ref et lb_nom.
On utilisera les règles de symbologie pour n’afficher que les données correspondant au cd_ref courant :
Voici la présentation faite à l’occasion du séminaire utilisateur de QGIS des 10 et 11 décembre dernier.
Elle a été réalisée avec Inkscape et SOZI. Utilisez les boutons de la souris ou les flèches de votre clavier pour avancer/reculer. La molette ou les signes +/- pour zoomer/dézoomer.
Cette page est le résultat d’un travail mené en commun, en mars 2015 par 4 géomaticiens et informaticiens des CEN Rhône-Alpes (Rémy Clément, Guillaume Costes et Laurent Poulin) et Languedoc-Roussillon (Mathieu Bossaert)
Elle a été actualisée le 17 mai 2018.
OpenDataKit est une suite d’outils libres dédiée à la collecte de données sur terminaux mobiles Androïd.
D’une relative simplicité de mise en oeuvre, la solution permet facilement de décrire et créer des formulaires correspondant à nos besoins. Une fois les données récupérées, il est simple de les intégrer à notre base de données en place.
Nous allons donc passer en revue l’installation des outils de la suite, la définition du formulaire avec XLSForm, et la ventilation des données récoltées dans notre base de données « métier », SiCen.
Présentation générale
ODK est un générateur de formulaires Open Source pour Android. Il permet de collecter des données en mode déconnecté. Les données sont envoyées quand une connexion est disponible, ou par upload de fichiers.
Les formulaires sont créés de manière simple, en utilisant un outil dédié (ODKBuild) ou en les décrivant dans un fichier excel avec le standard XLSForm
Tous les types de données sont disponibles et disposent de « widgets » adaptés : dates, textes, nombres, booléens, geo. Tous les médias que peut créer votre appareil androïd peuvent être attachés à l’observation eux aussi : son, vidéo, photo.
Il est possible d’interroger de longs référentiels (ex. TAXREF), fournis en csv avec le formulaire.
« XLSForm est une norme de formulaires créée pour aider à simplifier la création de formulaires dans Excel ». C’est dans un tableur que nous allons décrire de manière simple la strcuture et la logique du formulaire.
Installée depuis le dépot des applications de google, elle va se connecter au serveur « Aggregate », récupérer et proposer au téléchargement la liste des formulaires disponibles. Puis envoyer à « Aggregate » les données collectées.
Installé au sein d’un réseau interne, Aggregate peut-être associé à MySQL ou PostgreSQL. Dans notre cas, il sera asoocié à PostGIS et stockera ses données dans le schéma « odk« de notre base de données « SiCen« .
Mise en œuvre au sein de l’intranet
Installation d’aggregate
Elle peut se faire simplement en utilisant une machine virtuelle, diffusée à prix libre depuis cet été : https://gum.co/odk-aggregate-vm
Dans notre cas, nous allons procéder au déploiement d’une application java sur un serveur Tomcat.
Il s’agit en fait d’un exécutable qui va générer l’archive .war et le script SQL de création de la base de données (base de données, utilisateur odk et schema), conformément aux paramètres renseignés. Les tables sont créées au lancement du war et à l’ajout de nouveaux formulaires
On exécute sur le serveur de base de données les commandes SQL générées. Elles vont permettre de créer les tables et autres objets de base de données nécessaires à Aggregate pour fonctionner.
Puis on déploie l’applicatiopn depuis l’interface de tomcat-manager ou en déplaçant le war dans le dossier webapps de tomcat
Mise en œuvre du formulaire
Nous avions le projet de réaliser une application mobile complète dédiée à l’outil WEB SiCen, permettant de saisir nos observations sur un terminal Android pour les retrouver dans l’interface web de SICEN, sans intervention de l’observateur, autre que d’envoyer les données du formulaire au serveur.
Besoin simple
Il nous faut collecter des données d’observations d’espèces, localisées. Elles sont collectées dans le cadre d’une étude et selon un protocole particuliers
-> une étude, un protocole, des localités sur lesquelles on observe des espèces
Un formulaire GeoODK
→ conçu avec XLSForm
Le fichier excel décrivant le formulaire ainsi que les ressources csv nécessaires à son fonctionnement sont présents dans l’archive ci-jointe : demo_aten.zip
Trucs et astuces
Pour éviter la demande d’ajout de groupe, lors des « repeat » : Supprimer dans le xml le jr template il est présent au début du xml dans la liste des balises champs du début
Possibilité de cumuler la fonction quick + search dans la colonne « appearance » du fichier excel des formulaires avec la fonction quick search(…)
Le widget date avec calendrier n’est pas adapté : mettre dans la colonne « appearance » no-calendar
Génération des noms de formulaire automatiquement en rajoutant une colonne « instance_name » dans l’onglet « settings » du fichier excel. En utilisant un champ calculé.
Des référentiels en csv générés depuis la base de données
ODK permet désormais d’associer au formulaire de grosses listes de références dans des fichiers csv. Elles seront diffusées à ODKCollect avec le formulaire. Ce dernier les transformera en base de données locale sqlite.
La fonction search() permet de filtrer les entrées proposées, à celle contenant la chaîne de caractèressaisie par l’utilisateur. Nous utiliserons cette possibilité pour la gestion des listes de choix relatives aux :
taxons observés
observateurs et structures
études et protocoles
Voici une démonstration du résultat
Création du fond de carte
L’application permet non seulement de créer tout type d’objet mais également d’embarquer sur le terminal des fonds cartographiques en local (pas de réseau nécessaire).
Les fonds doivent être au format mbtiles. Ils peuvent être généré avec TileMill, comme décrit dans la doc de GeoODK : http://geoodk.com/mbtiles_howto.php, ou d’autres outils.
Dans notre cas, nous utiliserons MOBAC parceque nous l’utilisons déjà. Par contre, le mbtile produit par MOBAC nécessitera une petite mabnipulation :
Ouvrir le fichier avec un sqlite manager et exécuter la requête suivante :
CREATE VIEW images as SELECT ROWID, « tile_data », tile_row as « tile_id » FROM « tiles » ORDER BY ROWID
Le fichier MBTiles correspondant aux fonds cartographiques doit ensuite être placé dans un sous dossier du dossier OfflineLayers : OfflineLayersSous_Dossier_contenant_Mbtiles.
Ventilation des données dans la base «métier»
Création d’une vue qui met les données au format propre à notre table de destination (saisie.saisi_obsevration)
Voilà donc nos données envoyées au serveur Aggregate, directement visibles et modifiables dans SiCen !
Conclusion / Bilan
Améliorations récentes
→ utilisation de gros référentiels + widget cartographique
Facilité de mise en œuvre de la solution
→ appli Android + déploiement WAR / Machine virtuelle
Souplesse / facilité de création de formulaires de saisie
→ Par des collègues non géomaticien / montée en compétence rapide
Intégration aisée au SI en place dans la structure
→ En utilisant les outils standards de notre base de données (vues et triggers)
Chaque donnée intégrée à la base de données de l’atlas doit être examinée (validée / invalidée). Afin de faciliter le travail de validation, les fonctions présentées ici, permettent de passer chaque donnée saisie au crible des connaissances actuelles sur l’espèce, issues de la base de données.
Chaque taxon a tout d’abord été « caractérisé » selon les connaissances actuelles mobilisables dans la base de données (données validées).
Pour chaque espèce ont donc été calculées les références suivantes :
liste des communes
liste des entités et des ensembles paysagers
lises des semaines et des décades d’observation
listes des observateurs ayant déjà une donnée validée pour ce taxon
la répartition altitudinale (plages de 100 m d’altitude, correspondant à la division entière de l’altitude par 100)
Pour chaque nouvelle donnée, ou à chaque modification d’une donnée, les valeurs saisies vont être confrontés à la grille précédemment calculée. C’est un trigger qui déclenche cette confrontation de la donnée saisie aux valeurs de référence pour le taxon
La fonction de comparaison qui est appelée par le trigger est la suivante :
Un « score » est affiché dans le champ « décision validation » afin de permettre aux validateurs de filtrer les données selon ce score.
Dés qu’une donnée est validée, la grille est recalculée pour le taxon concerné. Si une donnée anciennement validée est invalidée, les valeurs de référence pour le taxon sont aussi recalculées.
Au niveau de la base de données, c’est encore un trigger qui déclenche la mise à jour de la ligne de la grille relative au taxon mentionné dans la donnée.
Il appelle cette fonction, qui va supprimer la ligne de référence pour le taxon concerné et la réinsérer en tenant compte des nouvelles données validées :
Cette démonstration s’arrête au moment de l’envoi des données collectées au serveur, et de la démonstration de l’intégration automatique et instantanée des données à SiCen.







 Dans notre cas, nous allons procéder au déploiement d’une application java sur un serveur Tomcat.
Dans notre cas, nous allons procéder au déploiement d’une application java sur un serveur Tomcat. Besoin simple
Besoin simple