
Forum TIC 2019 – Présentation de redash
Présentation plus complète de redash à l’occasion du Forum TIC de l’AFB de 2019.

Les exemples :
- https://youtu.be/FWQ5Z4oAteA
- https://frama.link/redash_foncier_cenlr
Petit test de l’extension trackprofile2web de Faunalia
Avec un trail à venir en juin 😉
Super extension ! Merci Faunalia
Redash pour la création de rapports web
![]() Redash est une solution de reporting web, qui permet de mettre en forme des données sous la forme de tableaux, de graphiques ou de cartes.
Redash est une solution de reporting web, qui permet de mettre en forme des données sous la forme de tableaux, de graphiques ou de cartes.
Nous avons réalisé un rapide et subjectif comparatif pour le congrès des CEN du Havre d’octobre 2018 (http://si.cenlr.org/outils_web_de_reporting_congres_cen_2018).
Redash ne nécessite pas d’autre compétence que celle d’écrire des requêtes SQL.
Voici un cas d’utilisation récent au CEN, celui de mettre à jour une travail de synthèse des enjeux de biodiversité connus sur les Périmètres autorisés du CDL de la côte languedocienne.
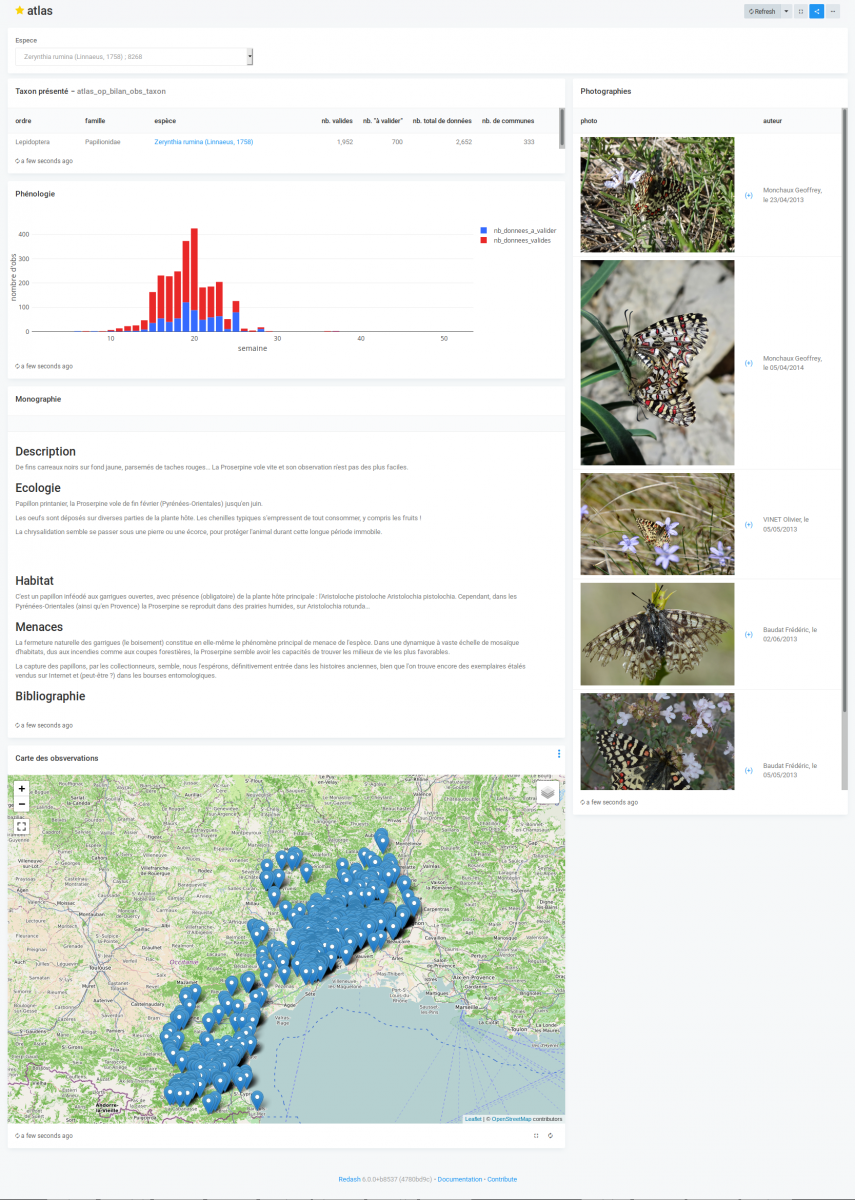
Un paramètre (liste déroulante des périmètres) est proposé en tête de rapport. La valeur de ce paramètre est répercutée dans les clauses WHERE des requêtes qui alimentent les tableaux.
Les tableaux listent les enjeux liés aux habitats naturels, à la faune et à la flore, connus dans notre base de données.
D’autres restitutions sont possibles (de nombreux types de graphiques, des cartes). Les cartes sont pour l’instant peu élaborées, assez peu élaborées mais on pourra contourner cette limitation par l’insertion d’une image, générée dynamiquement par un serveur cartographique.
D’autres examples de rapport plus complets, avec cartes et graphiques seront présentés ici (page d’atlas de répartition d’espèces, rapport d’évaluation agro-environnementale d’exploitation agricole…)
Voici une capture d’écran du rapport « atlas » qui interroge les donénes saisies dans l’Atlas des papillons de jours et des libellules du L-R
Attribution d’un UUID (id_permanent) en vue de la diffusion des données dans le SINP
Les données collectées à l’aide des formulaires ODK Collect sont identifiées par un uuid que nous récupérons dans notre base de données métier.
L’idée consiste à récupérer cet identifiant quand il existe, sinon a en générer un.
Dans notre base de données, cet uuid généré par odk est stocké dans le champ id_waypoint de la donnée, sous forme de texte, formaté comme ceci : uuid:d9efd9ee-0b21-40a9-8606-901a8766106a
Donc quand cet uuid existe, on le garde comme id_permanent, sinon on en génère 1.
https://framagit.org/mathieubossaert/sql_divers/snippets/3189
<sql>
</sql>
Rapportage automatique des enjeux de biodiversité et de l’analyse foncière
Les salariés du CEN ont régulièrement besoin de mobiliser des données géographiques relatives au foncier ou la biodiversité. En effet, lorsqu’une zone d’étude est désignée, il peut être intéressant de disposer d’une première liste d’informations qui apparaissent comme récurrentes dans les projets de protection et de conservation de la biodiversité.
Le CEN a besoin de connaître la liste des espèces (patrimoniales ou non) présentes sur le site, leurs statuts de protection ainsi que l’état de la population (vulnérable, en danger, danger critique…).
Il peut être intéressant également de savoir si ces espèces sont inscrites sur les listes rouges (nationales, régionales, européennes) ou sur les listes déterminantes ZNIEFF, ou encore si une espèce revêt un enjeu régional ou départemental fort.
Des informations relatives à la présence ou non de périmètres réglementaires ( N2000, RN…) et d’inventaires (ZNIEFF, ZICO) ainsi que les coordonnées foncières des propriétaires de terrain sont également mobilisés.
Le CEN travaille à plusieurs échelles différentes. Il peut être amenée à travailler sur un site protégé, à l’échelle de parcelles, de propriétés agricoles, d’une zone de prospection ou encore celle d’une commune ou de tout autre collectivité.
Le choix retenu ici implique pour l’utilisateur de dessiner une emprise sur Qgis ou de se baser sur un périmètre déjà existant (exemple d’une commune ou d’une parcelle), en fonction de sa zone d’étude, et d’intégrer cette information dans la couche postgis nommée « zone_analyse_reporting_biodiversite_foncier ».
Au moment de la création de la zone, un formulaire s’ouvre dans Qgis et demande à l’utilisateur de compléter plusieurs champs de la table (motif,nom_commune, nom_site, boîtes à cocher pour analyse_biodiversite et analyse_foncier). Le champ nom_site est spécifié comme obligatoire et permet de rapatrier le nom du site dans le titre de la vue créée en compagnie de la date du jour.
L’utilisateur peut donc choisir s’il exécute l’analyse de la biodiversité ou l’analyse du foncier sur la zone (ou les deux). Le formulaire est validé, puis la mise à jour est enregistrée, ce qui permet la création des vues. Le rafraîchissement des vues se fait également au moment de la mise à jour de l’entité.
Le trigger de PostgreSql permet de déclencher un programme qui s’exécute de manière automatique lorsqu’un évènement précis se produit sur une table.
Le programme est stocké dans une fonction affectée à la table concernée, ici la table zone_analyse_reporting_biodiversite_foncier. Ainsi, lors de l’édition de cette table, les vues suivantes sont créées :
- liste et localisation des espèces (faune/flore) présentes sur le site avec leurs statuts de protection associés, leur présence ou non dans un inventaire, leur vulnérabilité et leur niveau d’enjeu régional
- liste et localisation des espèces dites « patrimoniales » présentes sur le site et leurs statuts. Cette donnée comprend les espèces protégées au niveau national ainsi que celles issues de l’article 1 de la Directive Oiseaux
- liste des espèces par communes (sur une seule ligne)
- liste des communes par espèces (sur une seule ligne)
- liste et localisation des espèces présentes dans la ou les communes du site étudié
- liste et localisation des espèces dites « patrimoniales » dans la ou les communes du site étudié
- liste et localisation des espèces présentes dans les communes voisines de la commune du site étudié
- liste et localisation des espèces dites « patrimoniales » présentes dans les communes voisines du site étudié
- liste et localisation des périmètres réglementaires et inventaires qui croisent la zone étudiée
- Pour les salariés en charge de ces questions, la liste et localisation des parcelles et des coordonnées des propriétaires des terrains de la zone étudiée
Création de la table de dessin des zones d’analyse foncière et d’enjeux de biodiversité
Les vues sont consultables depuis Qgis. Le travail réalisé ici permet d’accéder à ces informations à partir d’une simple édition. L’équipe du CEN peut ainsi mobiliser ces informations en autonomie en quelques clics sur Qgis par le renseignement d’un formulaire. Il permet également de répondre à l’obligation de suivi des requêtes liées aux données foncières et de garder une trace des analyses effectuées.
Trigger et fonctions nécessaires au reporting automatique des enjeux de biodiversité et à l’analyse foncière
L’utilisation du trigger pourra être améliorée au fur et à mesure des besoins et intégrer également des analyses spatiales plus complexes.
intégration de la base de connaissance « statuts » de l’inpn
La base de connaissance « Statuts des espèces » de l’INPN est disponible ici : https://inpn.mnhn.fr/telechargement/referentielEspece/bdc-statuts-especes
Le travail ci-dessous consiste à créer une matrice listant pour chaque taxon (en ligne), la valeur éventuelle le concernant pour chacun de statuts listés. Nous avons ajouté au travail de l’INPN des statuts de hiérarchisation locaux pour les ENS (11 et 66) ainsi que les espèces ZNIEFF à critères et remarquables, les listes rouges régionales oiseaux et odonates.
Les fichiers csv sont importés tel quels dans la BDD PostgreSQL dans deux tables : bdc_statuts et bdc_statuts_types.
PostGIS Raster – Altitude moyenne des bâtiments de Montpellier
La BD TOPO de l’IGN est stockée en base dans le schéma ign_bd_topo.
La commune de Montpellier compte 9014 objets dans la table bati_indifferencie. Le MNT est dans la table ign_bd_topo.mnt34.
WITH
pixel_concernes AS (
SELECT bati_indifferencie.id, (ST_DumpAsPolygons(ST_clip(rast, bati_indifferencie.geometrie))).val AS altitude
FROM ign_bd_topo.mnt34 AS altitude
JOIN ign_bd_topo.bati_indifferencie ON st_intersects(rast,geometrie)
JOIN ign_bd_topo.commune ON st_intersects(commune.geometrie,bati_indifferencie.geometrie)
WHERE commune.nom = 'Montpellier'
)
SELECT id, avg(altitude)
FROM pixel_concernes
GROUP BY id
Cours BTSA GPN Pole-Sup 2019
Le daporama et les données sont ici
C’est la fin de l’année, je soutiens mes assos préférées et donc GeoRezo
GeoRezo est une association à but non lucratif dont le fonctionnement quotidien repose sur le bénévolat de ses membres et sur le dynamisme de ses contributeurs.
Financièrement, l’association existe grâce aux dons de ses sympathisants et aux adhésions de ses modérateurs.
Les charges annuelles inhérentes à la vie du portail et de l’association s’élèvent à 2500 euros.
Le poste principal de dépense est lié à l’hébergement de l’infrastructure (70% des charges).
Votre don participera très concrètement au maintien des services proposés par le portail à votre communauté d’utilisateurs.
Par ailleurs, GeoRezo étant une association reconnue d’intérêt général, votre don est déductible de vos impôts à hauteur de 66 % des sommes versées (dans la limite de dons représentant 20 % du revenu imposable). Plus d’informations ici : https://www.service-public.fr/particuliers/vosdroits/F426
https://www.donnerenligne.fr/georezo-le-portail-geomatique/faire-un-don
Premier test – enfin – de Time Manager
1er test de l’extension Time Manager de QGIS pour montrer la progression de notre connaissance du territoire.
En rouge les données d’espèces animales en vert les données d’espèces végétales.

A reproduire avec nos données de maîtrise foncière et d’usage, et à l’échelle du Réseau des CEN !
Et voilà pour la gestion (maîtrise foncière et d’usage) : Les propriétés en rouge et les « conventions » en vert

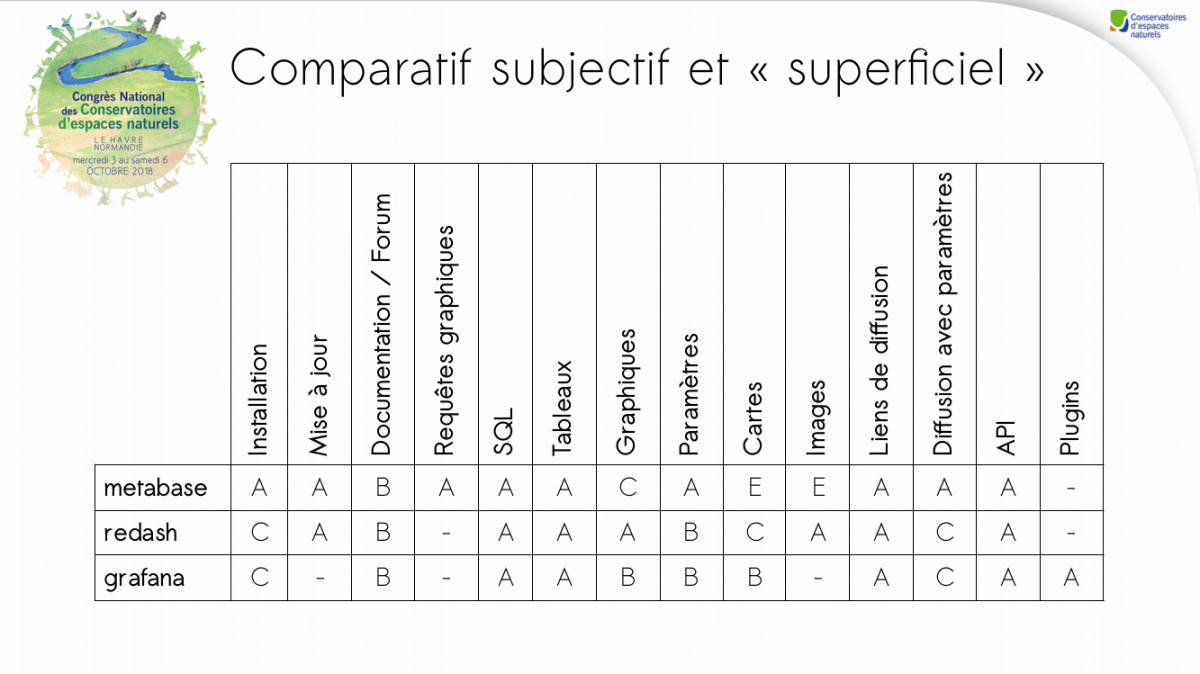
Congrés des CEN 2018 – Comparaison subjective et partielle d’outils web de création de tableaux de bord
Présentation réalisée pour l’atelier géomatique du Congrès des CEN du Havre, le 4 octobre 2018. Cliquez sur la première page pour télécharger le pdf.





Import de données dans SICEN
Intégrer des données externes à notre propre base de données peut se révéler fastidieux. pour faciliter la chose, nous allons créer une table qui décrit pour chaque table de données à intégrer, la liste des champs à y ajouter pour pouvoir ensuite les intégrer à sicen. Nous décrirons dans cette table comment le champ « sicen » doit être généré à partir des colonnes de la table à intégrer.
CREATE TABLE donnees_externes.insertion_sicen (
gid serial NOT NULL,
table_schema text, --le nom du schéma contenant la table à importer
table_name text, --le nom de cette table à importer sicen_id_obs text,
sicen_cd_nom text, sicen_date_textuelle text,
sicen_observateurs text, sicen_structure text,
sicen_remarque text, sicen_date_integration text,
sicen_date_obs text, sicen_precision text,
sicen_geom text, sicen_date_debut text,
sicen_date_fin text, sicen_effectif text,
sicen_effectif_min text, sicen_effectif_max text,
sicen_effectif_textuel text, sicen_type_effectif text,
sicen_remarque_localisation text, sicen_statut_validation text,
CONSTRAINT insertion_sicen_pkey PRIMARY KEY (gid) );

Une fois cette table créée et renseignée, la requête ci-dessous génère les commandes SQL de création des champs nécessaires à SICEN dans la table à importer, les met à jour.
SELECT * FROM (
SELECT DISTINCT concat('
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_id_obs INTEGER;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_cd_nom text;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_date_obs date;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_date_debut date;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_date_fin date;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_date_textuelle text;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_observateurs text;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_structure text;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_remarque text;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_date_integration date;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_precision saisie.enum_precision;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_remarque_localisation text;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_statut_validation saisie.enum_statut_validation;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_effectif integer;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_effectif_min integer;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_effectif_max integer;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_effectif_textuel text;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_type_effectif text;
ALTER TABLE ',table_schema,'."',table_name,'" ADD COLUMN sicen_geom geometry(geometry,2154);'
)
FROM donnees_externes.insertion_sicen
WHERE table_name ='_2018_flore_patrim_tuchan_2015'
UNION
SELECT DISTINCT concat('
UPDATE ',table_schema,'."',table_name,'" SET sicen_id_obs = nextval(''saisie.saisie_observation_id_obs_seq''::regclass);
UPDATE ',table_schema,'."',table_name,'" SET sicen_cd_nom = ',sicen_cd_nom,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_date_integration = now()::date;
UPDATE ',table_schema,'."',table_name,'" SET sicen_date_obs = ',sicen_date_obs,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_date_debut = ',sicen_date_debut,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_date_fin = ',sicen_date_fin,';
PDATE ',table_schema,'."',table_name,'" SET sicen_date_textuelle = ',sicen_date_textuelle,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_observateurs = ',sicen_observateurs,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_structure = ',sicen_structure,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_remarque = ',sicen_remarque,';
UPDATE ',table_schema,'."',table_name,'" SET date_integration = ',sicen_date_integration,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_precision = ',sicen_precision,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_geom = ',sicen_geom,';')
FROM donnees_externes.insertion_sicen
WHERE table_name ='_2018_flore_patrim_tuchan_2015'
--ORDER BY table_name, ordinal_position
UNION -- nécessaire car le nombre de paramètre passé à la fonction concat() est limité
SELECT DISTINCT concat('
UPDATE ',table_schema,'."',table_name,'" SET sicen_effectif = ',sicen_effectif,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_effectif_min = ',sicen_effectif_min,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_effectif_max = ',sicen_effectif_max,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_effectif_textuel = ',sicen_effectif_textuel,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_type_effectif = ',sicen_type_effectif,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_remarque_localisation = ',sicen_remarque_localisation,';
UPDATE ',table_schema,'."',table_name,'" SET sicen_statut_validation = ',sicen_statut_validation,'; ')
FROM donnees_externes.insertion_sicen
WHERE table_name ='_2018_flore_patrim_tuchan_2015'
) foo
ORDER BY 1
Le code généré est celui-ci (on export le résultat dans un fichier texte sinon pgadmin le tronque à l’affichage.
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_id_obs INTEGER;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_cd_nom text;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_date_obs date;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_date_debut date;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_date_fin date;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_date_textuelle text;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_observateurs text;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_structure text;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_remarque text;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_date_integration date;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_precision saisie.enum_precision;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_remarque_localisation text;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_statut_validation saisie.enum_statut_validation;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_effectif integer;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_effectif_min integer;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_effectif_max integer;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_effectif_textuel text;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_type_effectif text;
ALTER TABLE donnees_externes."_2018_flore_patrim_tuchan_2015" ADD COLUMN sicen_geom geometry(geometry,2154);
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_id_obs = nextval('saisie.saisie_observation_id_obs_seq'::regclass);
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_cd_nom = code_nom;
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_date_integration = now()::date;
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_date_obs = CASE WHEN outils.isdate(CONCAT(annee,'-',lpad(mois::text,2,'0'),'-',lpad(jour::text,2,'0'))) THEN CONCAT(lpad(jour::text,2,'0'),'-',lpad(mois::text,2,'0'),'-',annee)::date ELSE NULL END;
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_date_debut = CASE WHEN outils.isdate(CONCAT(annee,'-',lpad(mois::text,2,'0'),'-',lpad(jour::text,2,'0'))) THEN CONCAT(lpad(jour::text,2,'0'),'-',lpad(mois::text,2,'0'),'-',annee)::date ELSE NULL END;
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_date_fin = NULL;
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_date_textuelle = CONCAT(lpad(jour::text,2,'0'),'-',lpad(mois::text,2,'0'),'-',annee);
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_observateurs = trim(CONCAT(obs_1, ' & ', obs_2, ' & ',obs_3),'& ');
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_structure = structure;
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_remarque = NULL;
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_precision = CASE WHEN length(code_insee) = 5 THEN 'commune' ELSE 'supra-communal' END::saisie.enum_precision;
UPDATE donnees_externes."_2018_flore_patrim_tuchan_2015" SET sicen_geom = st_transform(geom, 2154);
Il ne me reste plus qu’à faire ma reqête d’insertion, à adapter selon les cas :
INSERT INTO saisie.saisie_observation(id_obs, date_obs, date_debut_obs, date_fin_obs, date_textuelle, regne, nom_vern, nom_complet, cd_nom, effectif,
effectif_min, effectif_max, effectif_textuel,longitude, latitude, localisation, numerisateur, code_insee, diffusable, "precision", statut_validation,
geometrie, nom_bdd, observateurs_pour_tri, structures_pour_tri)
SELECT sicen_id_obs, sicen_date_obs::date, sicen_date_debut, sicen_date_fin, sicen_date_textuelle, regne, nom_vern, taxref.nom_complet, sicen_cd_nom, sicen_effectif,
sicen_effectif_min, sicen_effectif_max, sicen_effectif_textuel, st_x(st_centroid(st_transform(geom,4326))),st_y(st_centroid(st_transform(geom,4326))), sicen_remarque_localisation, 7,
CASE WHEN length(code_insee::text)=5 THEN code_insee ELSE NULL END, false, sicen_precision::saisie.enum_precision, sicen_statut_validation, sicen_geom, 'ENS11',
sicen_observateurs, sicen_structure
FROM donnees_externes."_2018_flore_patrim_tuchan_2015"
JOIN inpn.taxref ON sicen_cd_nom::text = cd_nom
JOIN ign_bd_topo.commune ON st_intersects(commune.geometrie, st_centroid(geom));
Présentation d’ODK au FOSS4G-fr 2018
Du 15 au 17 mai 2018 se tenait à l’ENSG de Marne-la-vallée le FOSS4G-fr : https://www.osgeo.asso.fr/foss4gfr-2018/programme.html
Voici la présentation d’ODK réalisée pour l’occasion
Un grand merci aux organisateurs et aux intervenants pour cette journée (je n’ai pas pu rester le deuxième jour faute de temps) !

Calcul des aires d’occurences de taxons pour les listes rouges régionales
PostGIS 2.4 propose des fonction de fenêtre très pratiques pour les calculs d’aire d’occupation de taxon, utilisés dans la définition des listes rouges
Deux fonctions sont disponibles, ST_ClusterDBSCAN et ST_ClusterKMeans :
- https://postgis.net/docs/manual-dev/ST_ClusterDBSCAN.html
- https://postgis.net/docs/manual-dev/ST_ClusterKMeans.html
La requête ci-dessous créée l’aire d’occurence de l’espèce, pour les observations anciennes et récentes, en excluant les artefacts marins (découpage des périmètres produits selon les départements puis union des résultats)
WITH calcul_cluster AS (
SELECT id_entite, nom_ref , cd_ref, tous_point_espece_selon_format_esri.geometrie,
CASE WHEN annee<2007 THEN 'ancien' WHEN annee>=2007 THEN 'recent' END AS age,
ST_ClusterDBSCAN(tous_point_espece_selon_format_esri.geometrie, 25000, 1) OVER(PARTITION BY nom_ref, CASE WHEN annee<2007 THEN 'ancien' WHEN annee>=2007 THEN 'recent' END) as cluster_id
FROM public.tous_point_espece_selon_format_esri
JOIN departement ON st_intersects(departement.geometrie, tous_point_espece_selon_format_esri.geometrie)
WHERE statut_validation NOT IN ('non valide','douteux','accidentel')
AND "nom_reg" = 'LANGUEDOC-ROUSSILLON-MIDI-PYRENEES'
), cluster_entier AS (
SELECT row_number() OVER() as gid, nom_ref, age,
st_area2d(st_makevalid(st_multi(st_buffer(st_buffer(ST_ConvexHull(ST_Collect(geometrie)),1000),-900)))::geometry(MULTIPOLYGON,2154) )/1000000 as surf_km2,
st_makevalid(st_multi(st_buffer(st_buffer(ST_ConvexHull(ST_Collect(geometrie)),1000),-900)))::geometry(MULTIPOLYGON,2154) as geometrie
FROM calcul_cluster
GROUP BY nom_ref, cluster_id, age
)
SELECT row_number() OVER() AS id_noyau, nom_ref, age,
st_area2d(st_union(st_intersection(cluster_entier.geometrie, departement.geometrie)) )/1000000 as surf_km2,
st_union(st_intersection(cluster_entier.geometrie, departement.geometrie)) AS geometrie
FROM cluster_entier
JOIN departement ON st_intersects(cluster_entier.geometrie, departement.geometrie)
GROUP BY nom_ref, age